使用 SPIDR 拆出更小的 Story
最近團隊在做一個很大的專案,大家第一個想法就是按照設計稿不同 Section 拆成更小的 Story
但評估完之後,發現這樣根本做不完,會沒辦法如期上線
於是我們以 End-to-End 的方式重新再拆一次 Story
所以這篇文章是來分享如何以更系統性的方式將大張的 Story 拆分成更小張 Story,變成隨時可以 Deliver 的 Story
為什麼要拆分 User Story ?
- 為了能在一個 Sprint 內完成某些事情
- 這麼做可以帶來:
- 更高的透明度(讓你知道自己目前進度在哪裡)
- 更快的回饋
- 更快的學習
- 更快地交付價值
使用 SPIDR 拆 Story
當你發現一個 User Story 太大、太難估、不知道怎麼開始拆時,可以用 Mike Cohn 提出的 SPIDR 原則 來幫助你
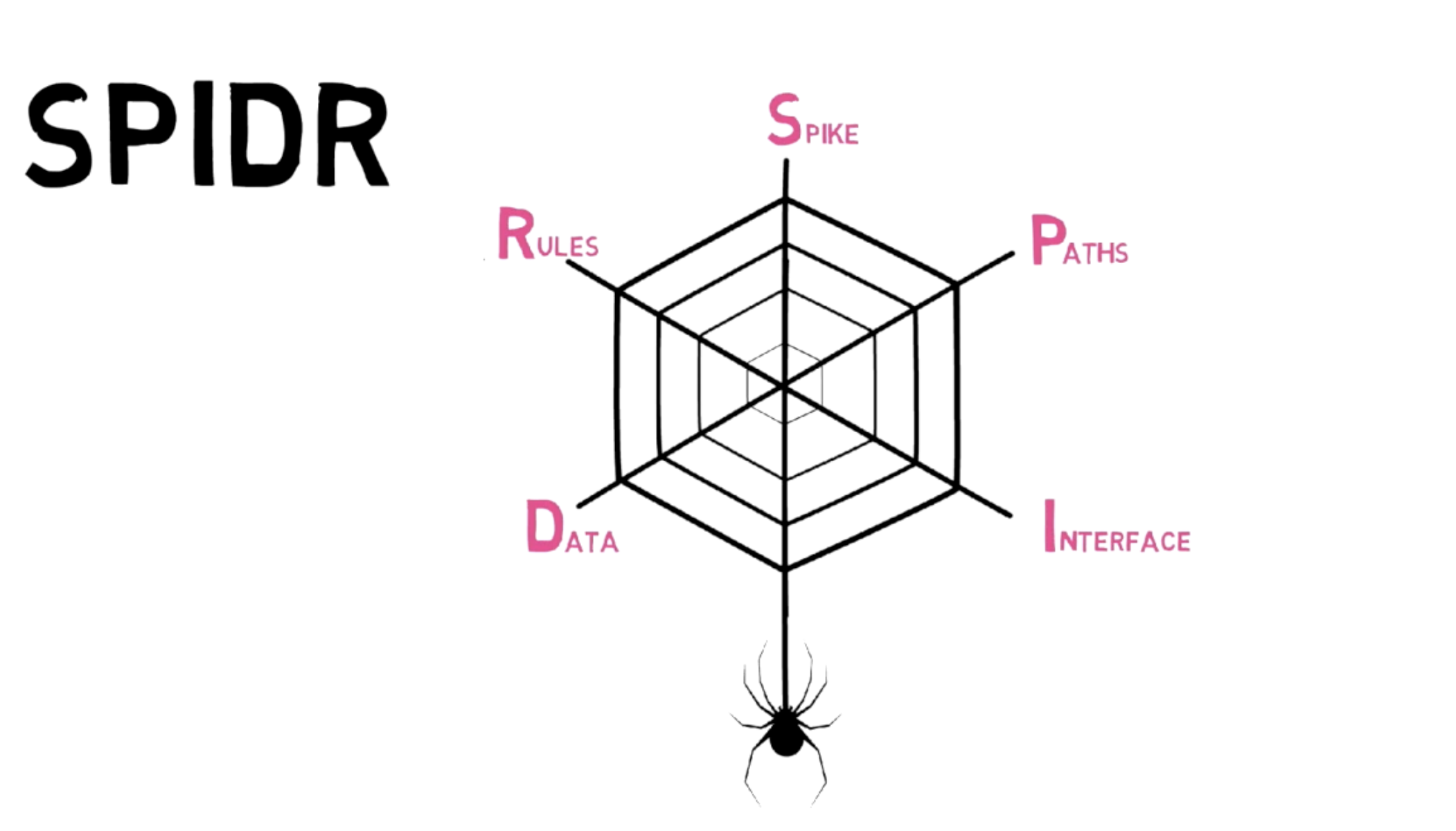
1. S – Spike(技術探索先拆出來)
如果你對某段技術還不確定(如第三方 API、硬體限制),可以先拆出一個「Spike Story」做研究
- ❌ 錯誤範例:「串接第三方支付並完成付款功能」
- ✅ 正確範例:「Spike:研究第三方支付 API 並記錄整合方式」
拆出 Spike Item 可以降低風險,讓估點更準確
2. P – Path(依照使用者操作路徑拆)
將一個故事依據不同的使用路徑拆開,例如成功流程與錯誤流程分開做
- ❌ 錯誤範例:「使用者可以登入系統(包含驗證失敗、忘記密碼等)」
- ✅ 正確範例:「使用者登入成功後可以看到首頁」+「登入失敗時出現錯誤提示」+「使用者可以透過忘記密碼重設帳號」
把不同的使用情境分開做,有助於優先交付核心功能
3. I – Interface(依畫面或裝置拆)
如果故事牽涉多個平台或不同 UI,先做一個、之後再擴展
- ❌ 錯誤範例:「使用者可以在所有裝置查看訂單」
- ✅ 正確範例:「使用者可以在桌機版查看訂單」+「使用者可以在手機版查看訂單」
先完成一個界面,也能交付價值,其他平台再逐步加上去
4. D – Data(依資料範圍或類型拆)
如果這個 Story 處理的資料種類很多,可以先從最基本的資料開始支援,再逐步擴充到完整資料
- ❌ 錯誤範例:「使用者可以編輯所有個人資料欄位(包含聯絡資訊、地址、付款資料、偏好設定等)」
- ✅ 正確範例:「使用者可以編輯姓名與 email」→ 下一個 Story 再支援地址與付款資料
減少一次處理所有資料欄位的壓力,優先完成使用頻率最高或風險最低的部分
5. R – Rules(商業規則延後處理)
若 Story 有很多驗證邏輯、複雜規則,可以先跳過部分規則,之後再補
- ❌ 錯誤範例:「建立訂單時需符合所有稅務規則、折扣機制與限制條件」
- ✅ 正確範例:「使用者可以下訂單(暫不處理折扣與稅金)」,下一版再加上「套用折扣規則」的 Story
先交付能運作的功能,之後再處理例外與複雜情境
這五種方法不一定要一次全用,但每次發現 Story 太大、沒信心估,就可以回頭檢查:
是否有可以拆成 Spike、路徑、介面、資料、或規則的部分?
也可以參考這個圖來幫助思考來拆 Story
結語:把 User Story 真正用起來
我們在這個系列文章中,一步步從基礎到實作,建立了使用 User Story 的完整心法:
- 在第一篇,我們理解了 User Story 是什麼、為什麼不是規格書,以及它如何幫助團隊聚焦在價值與溝通上
- 第二篇,我們學會了 如何用 INVEST 原則檢查 Story 是否夠好,避免掉進估不出點、無法驗收的坑
- 這一篇,我們則透過 SPIDR 技巧學會把大 Story 拆小成可以 deliver 的單位,真正能放進 Sprint、持續交付價值
拆 Story 不只是為了讓工作變得小塊好做,而是為了更快得到使用者回饋、更早交付價值,讓團隊成為真正敏捷的團隊
希望這系列能幫助你在寫 Story 時少一點卡關、多一點信心